| |
Since 2018, I have been
testing
Tesseract's OCR engine against the resolution of the
text. I wrote a script to auto-generate a test PDF file (here is an
example using Helvetica Narrow font)
with different resolution text in
six
different fonts (Helvetica, Times-Roman, Courier, Palatino, Bookman, and Helvetia-Narrow).
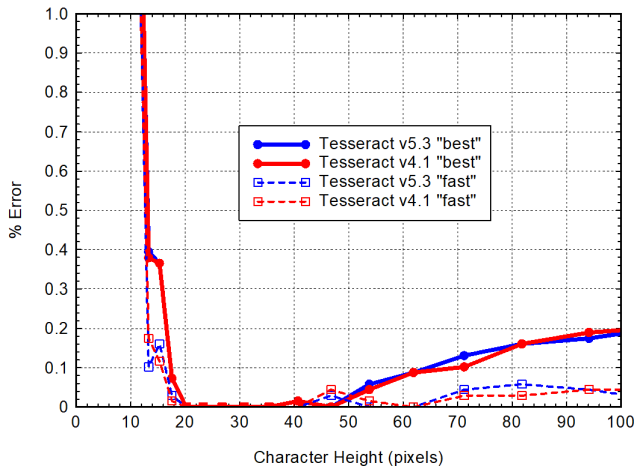
I then run Tesseract on the different PDF's and determine the accuracy of the OCR.
I characterize the resolution by the height of a typical capital letter in pixels.
It turns out that there is a sweet spot for Tesseract of about 30 pixels for the height
of a capital letter (seems strange to me that it would not continue to improve at higher
and higher resolutions, but okay). See the plot below. My software k2pdfopt uses this
result and tries to optimize OCR text size to be in this "sweet spot."
|
|
{kind=link}